
Most IT leaders have experienced it: a traffic spike hits, infrastructure strains, costs balloon, and the post-mortem reveals the team confused scalability with elasticity. Organizations often conflate these two concepts, leading to resource plans that either over-provision at great expense or under-deliver during demand surges. Cloud elasticity is not simply about growing your infrastructure. It is about growing and shrinking it intelligently, automatically, and in real time. This article breaks down exactly what cloud elasticity means, how it works in practice, which strategies and providers lead the field, and how your enterprise can harness it without falling into the most common and costly traps.
Table of Contents
- Defining cloud elasticity and why it matters
- How cloud elasticity works: Mechanisms and strategies
- Cloud elasticity in practice: Provider benchmarks and pitfalls
- Hybrid approaches and advanced best practices
- Our perspective: The uncomfortable truth about cloud elasticity
- Optimize your cloud strategy with our solutions
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Elasticity vs scalability | Elasticity lets you flex cloud resources instantly, while scalability focuses on predictable, stable growth. |
| Elasticity strategies | Effective approaches include reactive, predictive, scheduled, and hybrid scaling for different workloads. |
| Provider differences matter | Performance and burst capacity vary between AWS, GCP, and others, so compare before deploying. |
| Avoid common pitfalls | Combine elasticity with baseline capacity and multi-zone deployments for cost and reliability. |
| Hybrid model wins | Blending reactive and predictive methods delivers the most reliable results for enterprises. |
Defining cloud elasticity and why it matters
Cloud elasticity refers to the ability of a cloud environment to automatically provision and de-provision computing resources in direct response to workload fluctuations. When demand rises, resources scale out. When demand drops, those resources are released and costs reduce accordingly. This happens dynamically, often within seconds, without manual intervention.
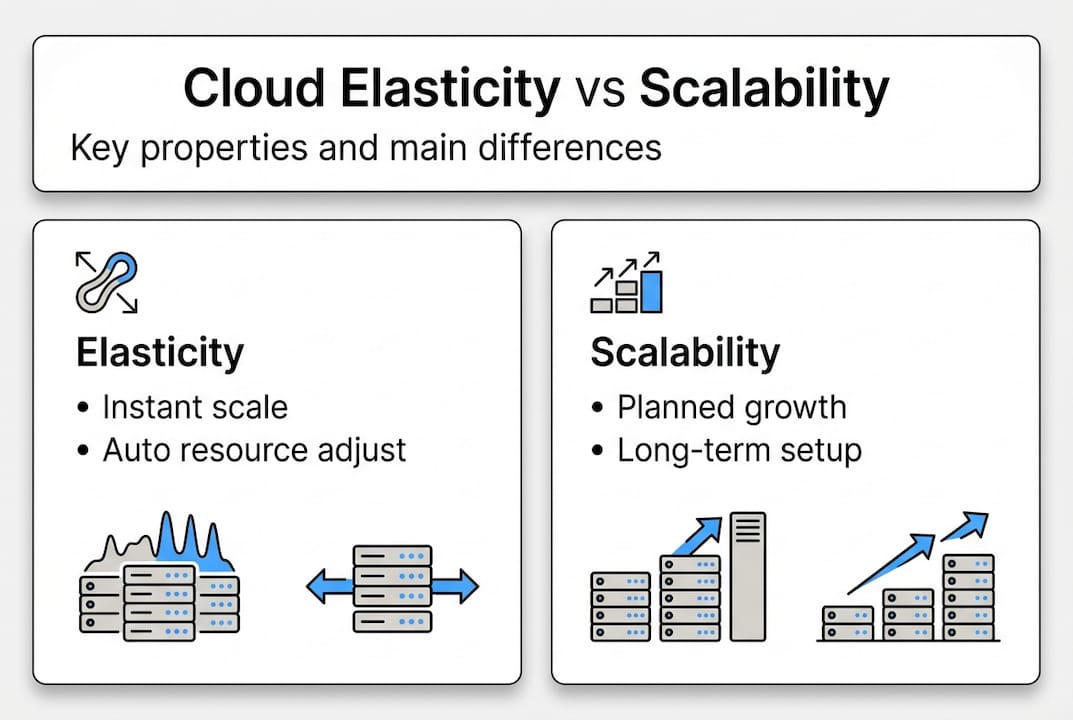
Scalability, by contrast, is a long-term architectural property. It describes how well a system can handle growth over time, typically through planned, stable increases in capacity. Think of scalability as expanding a warehouse and elasticity as renting temporary storage units during peak season. Both matter, but they solve different problems.
| Property | Cloud elasticity | Scalability |
|---|---|---|
| Response time | Real-time, automated | Planned, gradual |
| Cost model | Pay-as-you-use | Fixed or incremental |
| Best for | Variable, bursty workloads | Steady, predictable growth |
| Control method | Policy-driven automation | Architectural design |
Understanding reactive and predictive scaling methods is essential because each serves a distinct operational need. Reactive scaling responds to live metrics, while predictive scaling anticipates demand before it arrives.
The business benefits of cloud elasticity are direct and measurable:
- Cost efficiency: You pay only for what you consume, eliminating idle resource spend.
- Performance reliability: Applications maintain responsiveness even during unexpected traffic surges.
- Operational agility: Teams can respond to market changes without lengthy infrastructure procurement cycles.
- Risk reduction: Automated scaling reduces the likelihood of human error during high-pressure demand events.
For enterprises evaluating cloud vs traditional hosting, elasticity is one of the most compelling differentiators. Traditional hosting locks you into fixed capacity, while cloud environments built on solid cloud infrastructure basics allow your resource footprint to breathe with your business.
How cloud elasticity works: Mechanisms and strategies
At its core, cloud elasticity operates through auto-scaling engines that monitor workload signals and trigger resource adjustments based on defined policies. The moment a metric crosses a threshold, such as CPU utilisation exceeding 70%, the system provisions additional instances. When load subsides, those instances are terminated. This cycle repeats continuously and autonomously.
There are four primary scaling strategies, each suited to different operational contexts:
| Strategy | How it works | Best use case | Limitation |
|---|---|---|---|
| Reactive | Responds to live threshold breaches | Unpredictable traffic spikes | Latency between trigger and response |
| Predictive | Uses ML models to anticipate demand | Recurring workload patterns | Requires historical data to be accurate |
| Scheduled | Scales at pre-set times | Known events, batch jobs | Inflexible to unexpected changes |
| Hybrid | Combines reactive and predictive | Complex enterprise workloads | Higher configuration complexity |
Elasticity methods span reactive, predictive, scheduled, and hybrid strategies, each with distinct trade-offs that your architecture team must evaluate carefully before committing to a single approach.
Implementing elasticity effectively requires more than enabling auto-scaling. Follow these best practices:
- Define multi-metric policies: Do not rely on CPU alone. Combine memory, network throughput, and request queue depth for more accurate scaling decisions.
- Set appropriate cooldown periods: Prevent thrashing by allowing time between scale events before triggering the next adjustment.
- Integrate with Infrastructure as Code: Tools like Terraform or AWS CloudFormation ensure your scaling policies are version-controlled and reproducible.
- Test under simulated load: Validate that your policies respond correctly before a real traffic event exposes gaps.
Research into serverless benchmarks reveals that cold start latency and concurrency limits vary significantly across providers, which directly affects how your elasticity policies should be tuned. Understanding these nuances is part of building cloud infrastructure that performs under pressure.
Pro Tip: Combine latency metrics with queue depth signals in your scaling policies. A queue that grows faster than your processing rate is a far earlier warning sign than CPU utilisation alone, giving your system more time to scale before users feel the impact. Explore cloud scalability benefits to understand how this integrates with broader growth planning.
Cloud elasticity in practice: Provider benchmarks and pitfalls
Not all cloud platforms implement elasticity equally. Provider architecture, network topology, and runtime environments produce measurable differences in how quickly and reliably resources scale.

AWS Lambda burst capacity allows an initial burst to 3,000 concurrent instances in supported regions, while GCP demonstrates superior single-stream network throughput in comparative benchmarks. These differences are not trivial when designing multi-cloud or hybrid strategies.
| Provider | Burst capacity | Network throughput | Cold start latency |
|---|---|---|---|
| AWS Lambda | Up to 3,000 instances (burst) | Moderate | Low to moderate |
| GCP Cloud Functions | Region-dependent | High single-stream | Moderate |
| Azure Functions | Consumption plan auto-scales | Consistent | Low with premium plan |
For teams planning cloud hosting deployments, understanding these provider-level differences is critical. A workload optimised for AWS burst behaviour will not perform identically if migrated to GCP without policy adjustments.
Common pitfalls that undermine elasticity strategies include:
- Latency variability: Scale-out events introduce brief latency spikes that can affect user experience if not buffered by load balancers or caching layers.
- Unexpected cost escalation: Poorly configured scaling policies can trigger runaway provisioning during anomalous traffic events, producing bills that far exceed projections.
- Over-reliance on elasticity for steady workloads: Constant scale-in and scale-out cycles for predictable workloads waste resources and introduce unnecessary complexity.
- Ignoring provider quotas: Many providers enforce concurrency and instance limits that can cap your elasticity precisely when you need it most.
“Elasticity is a powerful tool, but it is not a substitute for sound baseline capacity planning. Teams that treat elasticity as a first resort rather than a complement to solid architectural foundations consistently encounter avoidable cost and performance issues.”
Pro Tip: Always establish your baseline steady-state resource requirements first. Size your reserved or committed capacity for that baseline, then layer elasticity on top to handle bursts. This approach consistently delivers better cost outcomes than relying on elastic scaling for all workload variations.
Hybrid approaches and advanced best practices
Hybrid elasticity combines reactive and predictive scaling into a unified strategy, capturing the responsiveness of threshold-based triggers and the foresight of machine learning models simultaneously. For enterprise workloads with both predictable patterns and occasional anomalies, this combination delivers the most reliable outcomes.
Hybrid reactive and predictive approaches deliver the highest enterprise satisfaction at 73%, and multi-zone deployments using these strategies achieve availability rates of 99.999%. These are not theoretical figures. They reflect real deployment outcomes across complex enterprise environments.
| Strategy | Enterprise satisfaction | Availability potential | Configuration complexity |
|---|---|---|---|
| Reactive only | Moderate | 99.9% | Low |
| Predictive only | High | 99.95% | High |
| Hybrid | 73% satisfaction | 99.999% | Medium to high |
Advanced best practices for enterprise elasticity include:
- Multi-metric scaling policies: Layer CPU, memory, network I/O, and application-level metrics for precision scaling decisions.
- Multi-zone deployments: Distribute workloads across availability zones to eliminate single points of failure and support near-perfect uptime targets.
- Chaos engineering: Chaos engineering testing is recommended specifically for validating elasticity schemes under failure conditions before production exposure.
- Continuous policy refinement: Treat scaling policies as living configurations. Review them quarterly against actual workload data and adjust thresholds accordingly.
For enterprises pursuing cloud migration for agility, hybrid elasticity is often the architectural pattern that justifies the migration investment. It enables the kind of operational responsiveness that on-premises infrastructure simply cannot replicate at comparable cost. Pairing this with scalable enterprise features ensures your digital presence scales in lockstep with your infrastructure.
Our perspective: The uncomfortable truth about cloud elasticity
Here is what years of working with enterprise cloud deployments have taught us: most organisations adopt elasticity because it sounds like a cost-saving measure, and then discover it can actually increase costs when implemented without discipline.
Elasticity is not a substitute for architectural clarity. When teams lack a well-defined baseline capacity model, they often configure scaling policies that react to noise rather than genuine demand signals. The result is constant thrashing, inflated cloud bills, and a false sense of control.
The real value of elasticity emerges when it is layered on top of a stable, well-sized foundation. Scalability handles your growth trajectory. Elasticity handles your variance. Conflating the two leads to systems that are neither cost-efficient nor reliably performant.
We also observe that many leaders treat elasticity as a technical concern rather than a strategic one. Decisions about scaling thresholds, provider selection, and hybrid strategies have direct financial and competitive implications. They belong in architecture reviews, not just in DevOps runbooks.
The future of cloud computing will demand even greater precision in resource management. Organisations that build elasticity on a foundation of sound baseline planning today will be far better positioned to leverage AI-driven scaling and edge computing workloads tomorrow.
Optimize your cloud strategy with our solutions
If this article has clarified where your current cloud resource strategy has gaps, the next step is translating that clarity into action. At CloudFusion, we design and build custom cloud solutions that incorporate elasticity from the ground up, ensuring your infrastructure scales intelligently without runaway costs. Our mobile app development services are built with cloud-native architectures that leverage elastic resource management for consistent performance under variable load. For teams needing reliable, scalable storage that adapts to demand, our cloud file storage solutions provide the flexible foundation your elasticity strategy requires. Reach out to discuss a tailored approach for your enterprise.
Frequently asked questions
What is the difference between cloud elasticity and scalability?
Elasticity handles bursts while scalability targets steady growth. Elasticity rapidly adds or removes resources in response to immediate demand, whereas scalability is a planned, architectural approach to long-term capacity increases.
When should my business prioritize cloud elasticity?
Prioritize elasticity when your workloads face unpredictable or seasonal demand spikes, such as e-commerce traffic surges. Elasticity is most valuable for bursty or highly variable workloads where over-provisioning would otherwise be the only alternative.
Which cloud platforms offer the best elasticity?
Both AWS and GCP offer advanced elasticity, but their strengths differ. AWS Lambda burst and GCP throughput benchmarks diverge significantly, making provider selection dependent on your specific workload profile and geographic requirements.
What are the risks of relying solely on elasticity?
Over-reliance on elasticity without a solid baseline capacity plan can produce cost spikes and performance degradation. Elasticity paired with baseline planning consistently outperforms elasticity used as the primary resource management strategy.
What is a hybrid cloud elasticity approach?
A hybrid approach combines reactive threshold-based scaling with predictive machine learning models. Hybrid approaches deliver higher satisfaction rates among enterprise teams and support significantly higher availability targets than either method used in isolation.
Recommended
- 7 Cloud Scalability Benefits for IT Managers in E-Commerce
- Enterprise Cloud Migration: Boosting Business Agility
- Cloud Hosting Pros and Cons – Business Impact Unpacked
- Benefits of Cloud Adoption – Boosting E-Commerce Efficiency
- Beyond Kilowatt Hours: How utilities can monetise demand-side flexibility






